

Mayhem Application Security
No false positives. Continually expanding coverage. Automated regression tests. It's what DevSecOps should be.

Evan Johnson
Head of Product Security

Trusted by



Reachable
Exploitable
Fixable
Mayhem was purpose-built to cut through the noise of traditional application security. Combining techniques used by attackers with generative AI, Mayhem tries to break your applications thousands of times every minute so you can find and fix the risks that matter most.
No Need to Recompile
Mayhem requires neither source code nor changes to your build, code or delivery.

Fits Into Your Development Pipeline
Mayhem fits into your existing development pipeline so your developers don't have to worry about security testing on top of everything else.
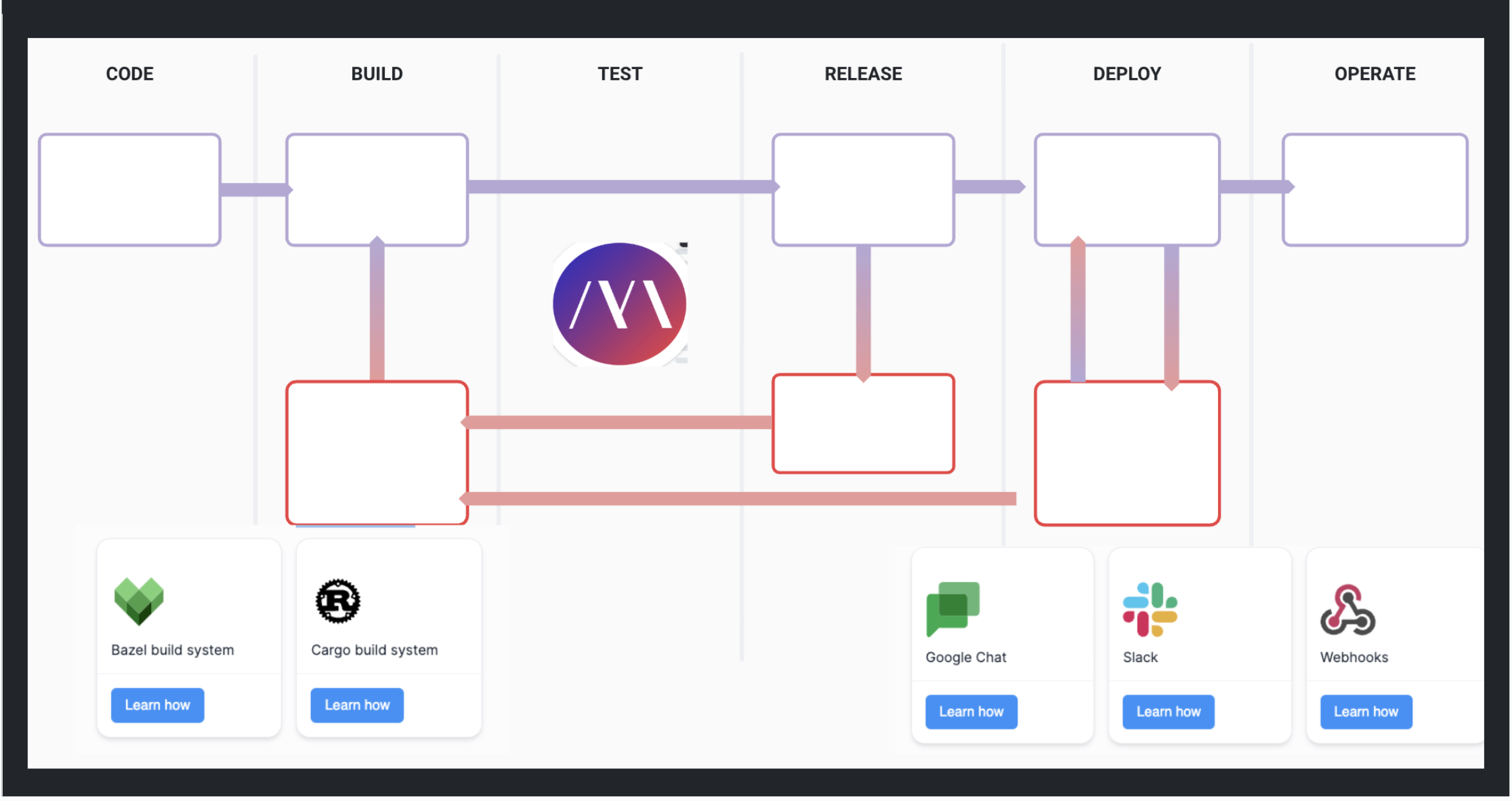
Continuously Test, Continuously Develop
Mayhem automatically generates and runs thousands of tests, so you can focus on development.

Fail Fast, Fix Often
Behavioral testing means every result is real and reproducible. Skip time wasted on triage and start fixing faster.

Secure Your Apps As You Build Them
Integrate with existing bug and crash systems for faster remediation and secure code releases.

Supply Chain Security
Since 2021, Mayhem has been integrated into thousands of open source projects, building a library of behavioral tests, identifying new zero-days, and helping defend against software supply chain threats
143,958,580,653
Tests created and executed
1,954
Repositories
2,755
Applications
102,108
Vulnerabilities Found
2,354,626
Regression Tests
.jpg)

No code changes or recompiling
Mayhem tests your actual code and not a proxy so you don't need to change your application just to secure it.








%20(1).png)
Seamless Integration
Put Mayhem where you need it most, with easy connections to crash reporting, CI/CD, IDE and issue tracking tools.
Mayhem Resources
Stay connected with the Mayhem team online, or come see us at an upcoming event.



Add Mayhem to Your DevSecOps for Free.
Get a full-featured 30 day free trial.
